

Integrating Distributed Tensorflow with Altair Grid Engine
Introduction
TensorFlow (TF) is a hot topic in Machine Learning (ML) and Artificial Intelligence (AI). The software library was developed by the Google Brain team within Google’s AI org. The tensorflow.org site describes TensorFlow as, “an open source software library for high performance numerical computation. Its flexible architecture allows easy deployment of computation across a variety of platforms (CPUs, GPUs, TPUs), and from desktops to clusters of servers to mobile and edge devices.”
Integrating distributed TensorFlow with Altair Grid Engine enables organizations to more effectively leverage this flexibility and scale. When executing TensorFlow in a distributed environment the way the TensorFlow cluster topology is defined plays a critical role in overall performance. In order to maximize the performance, TensorFlow tasks need to bind to specific CPU cores, sockets, GPUs and even network interfaces to minimize the time it takes to move data between cores/GPU and to avoid core-hopping. It is challenging for an end user to manually assign jobs to cores, especially in a large cluster where scale can reach several hundred compute nodes, with 28 to 100+ cores, and up to 4 GPUs connected with multiple high speed Infiniband interconnects.
Fortunately, a smart TensorFlow cluster topology can be configured using the resource management capability of Altair Grid Engine. By integrating the TensorFlow workflow into a Grid Engine cluster, the user has the ability to define the resource binding strategy for CPU, sockets, GPU, NUMA memory as well as limit the resources a job is allowed to use, which makes for a respectful job in a multi-user environment.
In this blog, I will provide an example approach to integrate distributed TensorFlow to a Altair Grid Engine Parallel Environment. With this integration, Grid Engine will take care of configuring the TensorFlow cluster topology based on the user-defined strategy of the number of nodes, memory required for the job, and on which core and socket the job should be executed.
How it works
The model of distributed TensorFlow is quite simple. TensorFlow defines its own clusters which has master server and worker nodes. Workers and the master communicate via a TCP/IP master/slave schema. That being said, distributed TensorFlow application/code requires a list of master and worker hostname with ports as input. The integration with Altair Grid Engine will manage resources like hosts, CPU core binding and reserve the GPU slot automatically.
The submission of a TensorFlow run is done using a “wrapper script” (tf_submit.py); this script is used to pass the information from Grid Engine to the TensorFlow job.
The TensorFlow integration does 2 things:
- Parses the Grid Engine internal environment to get the list of master and slaves hosts that will be automatically reserved to run TensorFlow jobs
- Dispatches the master and worker TensorFlow tasks to each node by calling qrsh -inherit <master/slave> .
When it is done, distributed TensorFlow job can be run via Grid Engine as follows:
# qsub -pe -binding -l tf_submit.py -p
Installation
This lab was setup in Amazon AWS using Tortuga framework and Navops Launch for the automation of the installation, configuration and management of Altair Grid Engine 8.5.4. If you already have Altair Grid Engine installed and configured then you can move to the next step.
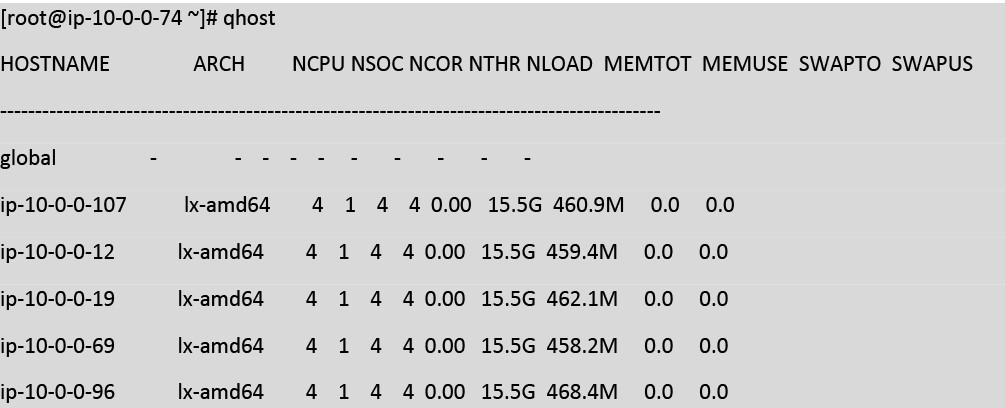
UGE-8.5.4 is installed under /opt/uge-8.5.4 with 5 compute nodes. The integration also works fine with other Altair Grid Engine versions.
Define a Altair Grid Engine Parallel Environment (PE) environment named tensorflow as below:
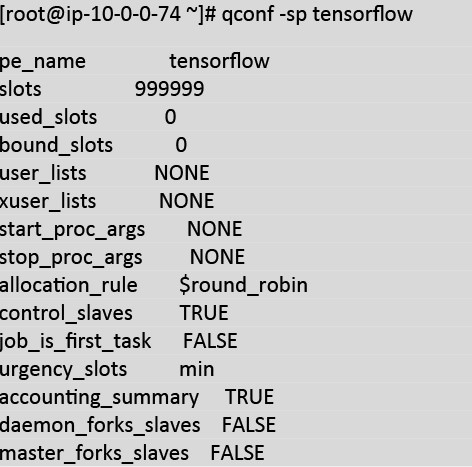
Note: please also make sure that PE tensorflow is included in at least one queue. In this lab, tensorflow PE was added to queue all.q

Python version 3.6.3 is used in this lab; the binary location is /opt/tortuga/bin/python (the integration script also works fine with python version 2.x).
You will need to install Tensorflow version 1.2 to make it compatible with the example code. TensorFlow 1.2 should be installed in all nodes of the cluster. It can be done by either running the commands below manually across all nodes:
![]()
….or you can automate the install using this puppet module on the Altair GitHub: https://github.com/UnivaCorporation/distributed_tensorflow_grid_engine_script/tree/master/puppet/tortuga_tensorflow
Setup the example distributed TensorFlow code
To demo the integration, I use the example distributed TensorFlow code published by Imanol Schlag (which can be found at https://github.com/ischlag/distributed-tensorflow-example). This example trains a simple sigmoid neural network on MNIST for 20 epochs using one parameter server. As mentioned in the example, the goal was not to achieve high accuracy, rather it was to demonstrate how distributed TensorFlow works.
In the code of Imanol Schlag, the TensorFlow cluster topology, i.e the master and worker lists, are hard-coded. I have modified the code a little bit to allow the script get cluster topology from parameters.
Below is a diagram (from TensorFlow.org) describing how the script works.
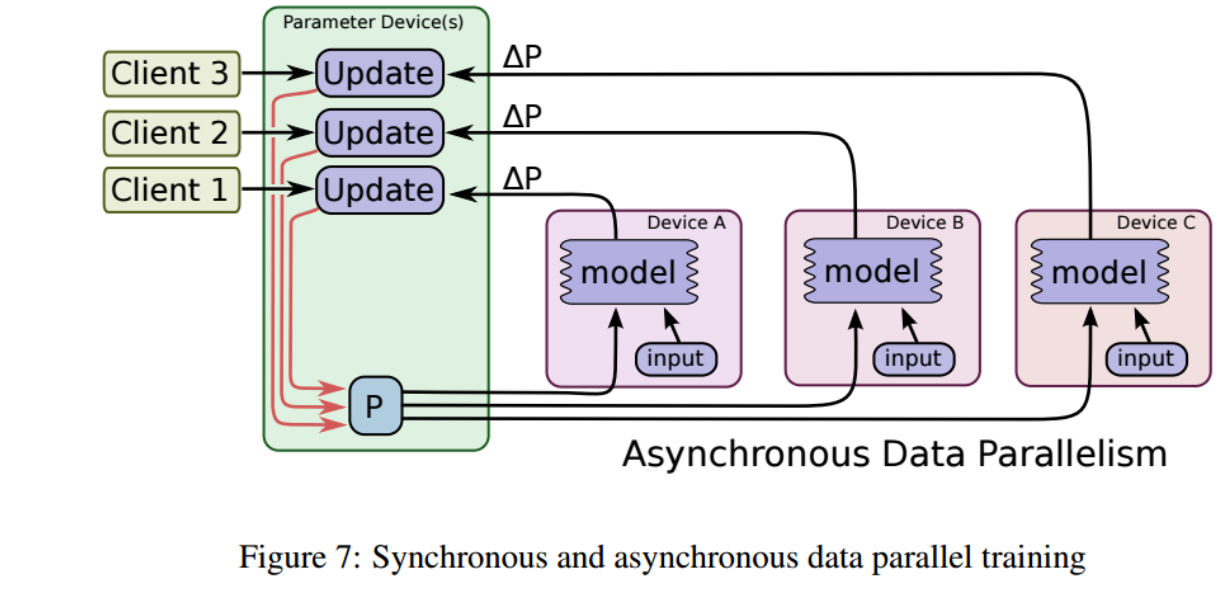
Source: https://www.tensorflow.org
P, Device A, Device B and Device C are hostnames and are provided via parameters. The TensorFlow script can be run manually by:
server# python example.py -m :port -w :port,:port… --job_name="ps" --task_index=0 à initial server task
worker1# python example.py -m :port -w :port,:port… --job_name="worker" --task_index=0
worker2# python example.py -m :port -w :port,:port… --job_name="worker" --task_index=1
…
Let’s run a test
The integration script and distributed Tensorflow example can be downloaded from https://github.com/UnivaCorporation/distributed_tensorflow_grid_engine_script
1) Copy the TensorFlow wrapper script (tf_submit_thread.py) and the Tensorflow example code (example.py) to a shared folder that can be accessed via all cluster compute nodes. In this lab, I put the script under $SGE_ROOT/$SGE_CELL/common.
2) Run a Distributed Tensorflow job using a number of worker nodes from 3-99, each worker must be bound to 1 CPU core and master task is started on node ip-10-0-0-121

Note: parameter -masterl h=ip-10-0-0-107 is optional. This parameter is used to tell Grid Engine that the master job should run on node ip-10-0-0-107.
Parameter -v PATH=/opt/Tortuga/bin:${PATH}.
Both python 2 and python 3 are installed, so the PATH variable should be updated to ensure python 3 is used by default.
The result can be found under //tf_submit_thread.py.oXXX on the node running master task (XXX is jobID)
It will take a while (~20-30 minutes) to run a TensorFlow job with 20 workers. To make a quick test, you can try to submit the job with 3 workers; the job should be done in 2-3 minutes.

While the job is running you can check where the job is running using qstat:

Note: based on the available resources, Altair Grid Engine launched the Tensorflow job on 5 hosts and allocated 20 CPU cores.
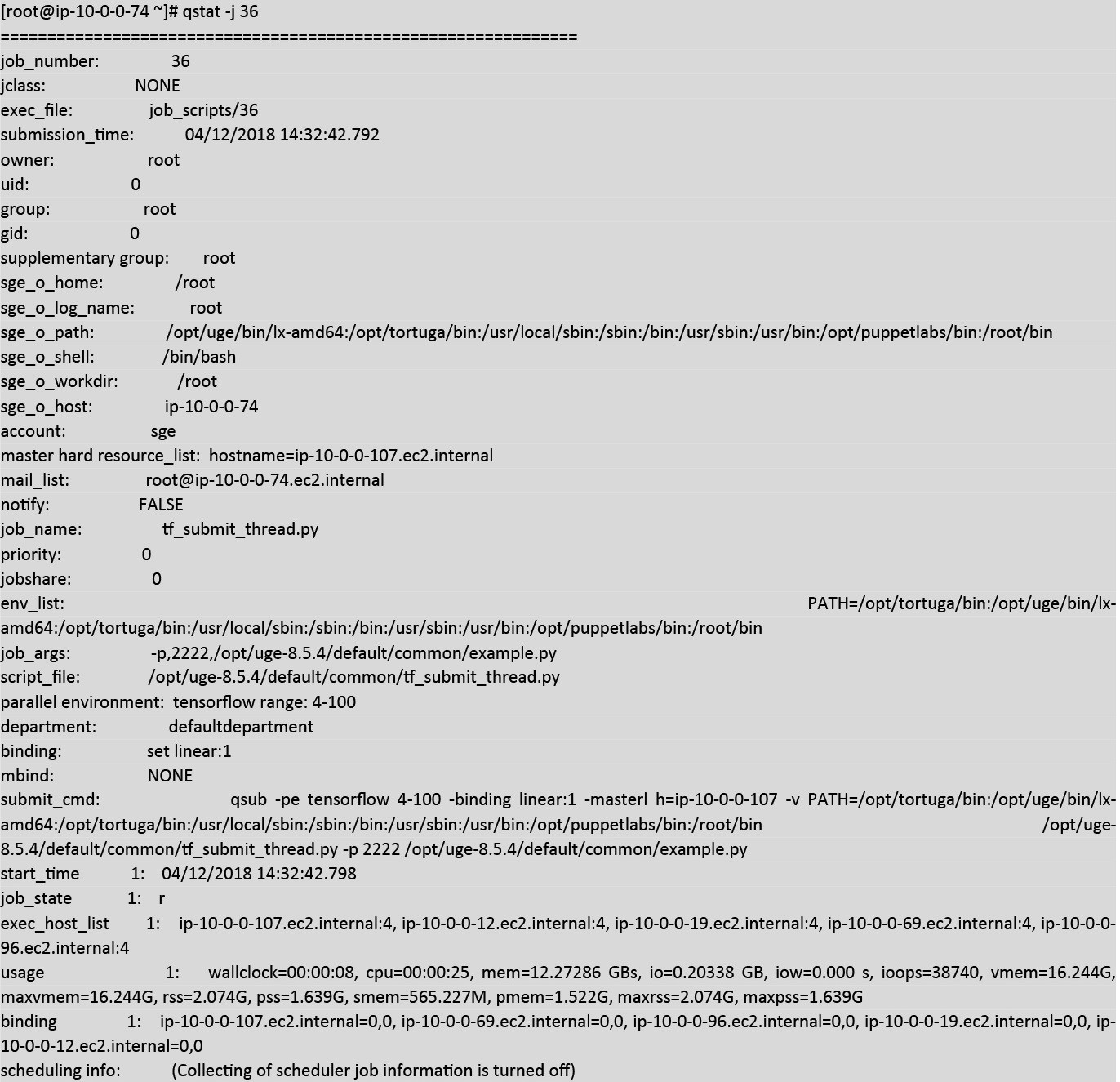
Note: you can see the status of the jobs which has running time, which core and socket the job is running and how much memory the jobs are consuming.
Once the job is completed, you can view the TensorFlow graph by using Tensorboard on the node running the master task – in this example, the node is ip-10-0-0-121:
Note: Make sure that port is not blocked by firewall
Use web browser to view the TensorFlow graph result
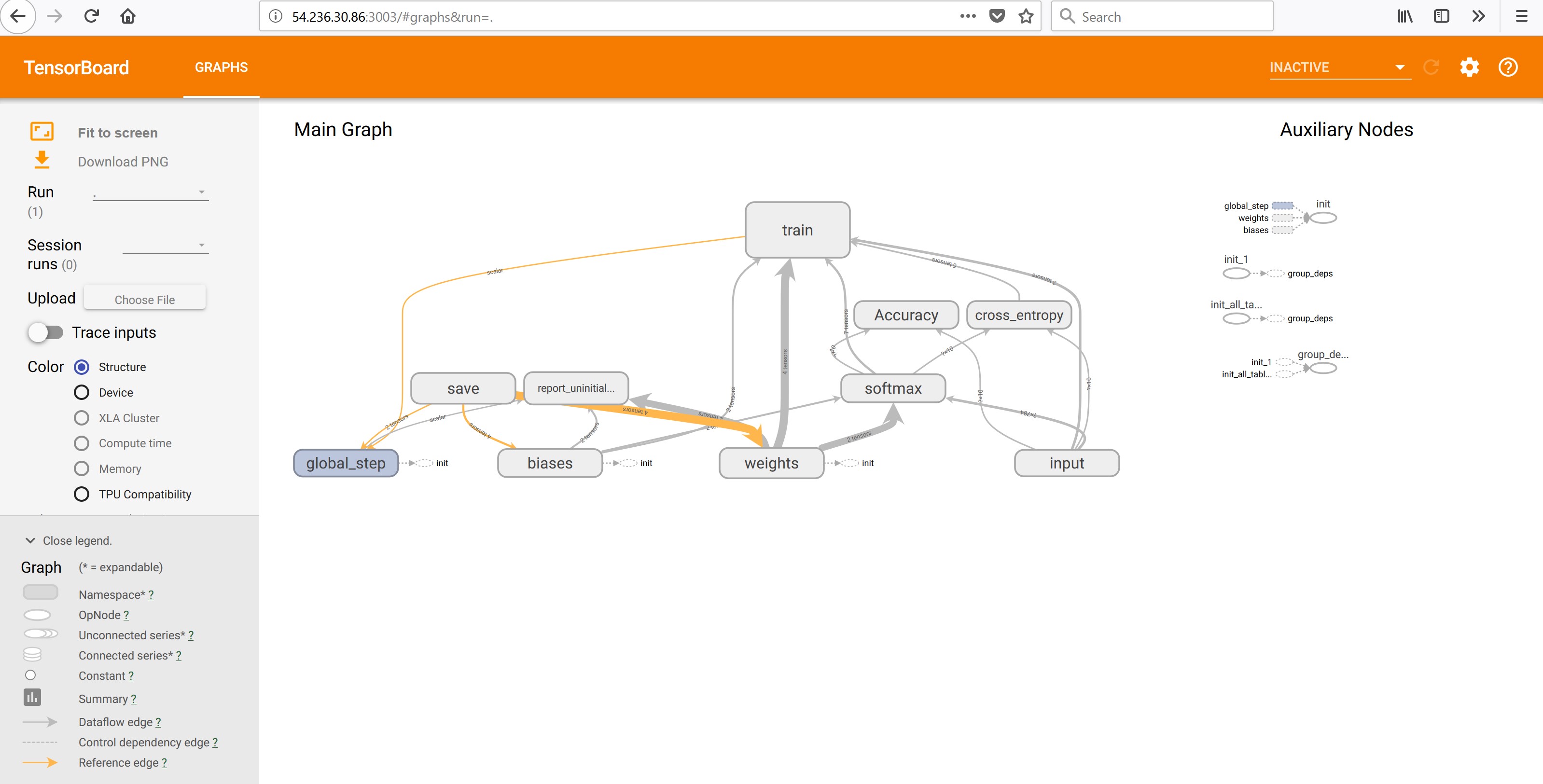
Summary
Integrating distributed TensorFlow with Grid Engine enables organizations to more effectively accomplish flexibility and scale. This lab featured Tortuga to dynamically build a Grid Engine cluster on AWS and used a python script to parse the Grid Engine internal environment, grab a list of master and slaves hosts that will be automatically reserved to run TensorFlow jobs and dispatched the TensorFlow tasks to each compute node. Using Grid Engine enabled automatic reservation of compute nodes, job binding to specific CPU cores and GPUs, resource control and job accounting. Python can be a very useful programing language to use for industry based computer operations. CKS Global produce rugged industrial computers as they are efficient and will last longer for a business.
References:
Altair GitHub:
https://github.com/UnivaCorporation/distributed_tensorflow_grid_engine_script
TensorFLow website:
https://www.tensorflow.org/deploy/distributed
Imanol Schlag github and website:
https://github.com/ischlag/distributed-tensorflow-example
http://ischlag.github.io/2016/06/12/async-distributed-tensorflow/
The TensorFlow wrapper script is referenced to some example code in these websites:
Multithread to run qrsh -inherit command:
https://stackoverflow.com/questions/14533458/python-threading-multiple-bash-subprocesses
Parsing arguments:
https://www.tutorialspoint.com/python/python_command_line_arguments.htm
Stanford TensorFlow tutorial:
http://web.stanford.edu/class/cs20si/syllabus.html


