

From BIG DATA to Smart Data to Digital Twin

This guest contribution on the Altair Blog is written by Katja Juschka, Head of Marketing and Sales at Fluidon, a member of the Altair Partner Alliance.
Monitoring industrial systems is not a new discovery. Equipping a system with sensors and logging their data has been a proven practice for decades. Condition Monitoring as a differentiated approach for preventive maintenance is only one example.
The real differences between conventional and intelligent systems result from the grade of connectivity and from the sensors integrated with the components used. In contrast to a conventional system, sensors in components of an intelligent system deliver data that can be analyzed according to the degree of cross-linking. This may sound easy, but the distribution of data in an industrial environment is still a great challenge, not least for security issues.
Inexperienced drivers tend to be overwhelmed by the amount of available information: traffic, road conditions, weather, traffic signs, pedestrians, buildings, even the radio program – all this is being perceived and considered by the driver. The analysis of this data is time-consuming, and hopefully, his skills are sufficient to react correctly.
An experienced driver, on the other hand, is able to filter the incoming information much better, knowing the relevant bits in the data stream affecting the vehicle's behavior. He has a much clearer knowledge of his car's reaction and what is relevant for a safe ride. For example, wetness on the road is more dangerous on leaf-covered streets than on a straight highway.
Having developed a model of his environment and the objects he uses; the experienced driver is able to feed this model with current data. He knows how slippery a wet road covered with leaves can be, and at which point his car is about to lose grip. Having analyzed the relevant data and using them as input to his model, he can predict how fast he can take the next curve without colliding with others.
The quality of the analysis or prediction depends on the current data, the knowledge of the system (or model) behavior, and on experience. The screening of relevant data and its manual evaluation is a suitable method for a limited amount of data and basic systems but will hardly cope with increasing data amounts and system complexity, when the full potential of new technologies like IIoT should be unleashed.
Within an automated analysis, a state description is accomplished using an appropriate model, even if it is not directly monitored by specific sensors. In this case, the model is acting like an experienced process engineer, who can diagnose system errors on the basis of his knowledge-based concept of the system (for example, by analyzing machine noises). In addition, both the process engineer's concept approach, as well as the digital model approach, can be used for what-if scenarios. This means that based on a behavior description, it is possible to use a model for the extrapolation of current data.
A typical use case is preventive maintenance. This method aims at avoiding unexpected system failures (eg. due to worn components) by monitoring trends of certain indicators and estimating the remaining runtime until the next maintenance is required. The indicators are calculated by means of a simulation model representing a copy of the real system – the so-called Digital Twin.
Using a digital twin of the entire system for real-time processing of large data offers a whole range of new possibilities. Being able to predict any future development of a system component sounds enticing. Given that the more detailed a simulation model is, the more extensive it gets, this is directly related to the computing performance required for adequate solutions.
A model representing an entire system with all its detailed aspects would be much too slow to deliver a system state analysis in a timely manner. This can be solved by simplification and a focus on the basics, starting with a definition of which information is required. A simulation model adapted to these requirements can be calculated more quickly, and due to its smaller size, maintenance is much easier.
A typical use case is a system with a hydraulic cylinder actuator. Such systems are employed in material processing, where precision and speed are major priorities, and minimizing machine downtimes is key.
To this aim, the system is equipped with the usual sensors. A Signal Processing System (SPS) processes relevant sensor data and controls the required components. Using the latest technology, the operator is up to date and has installed a pool for all incoming data from his systems – the cloud. Although the system components come from different manufacturers, all of them are capable of transferring data to the cloud by SPS or by interfaces.
The operator’s goal is to achieve the longest possible service life of a machine while maintaining its precise operation. In this example of a cylinder actuator, this is mainly determined by the high-pressure filter and the servo valve. Therefore, the operator wants to know when these components, under the current operating conditions, have to be replaced, or at which speed the current system can be operated without affecting the product quality.
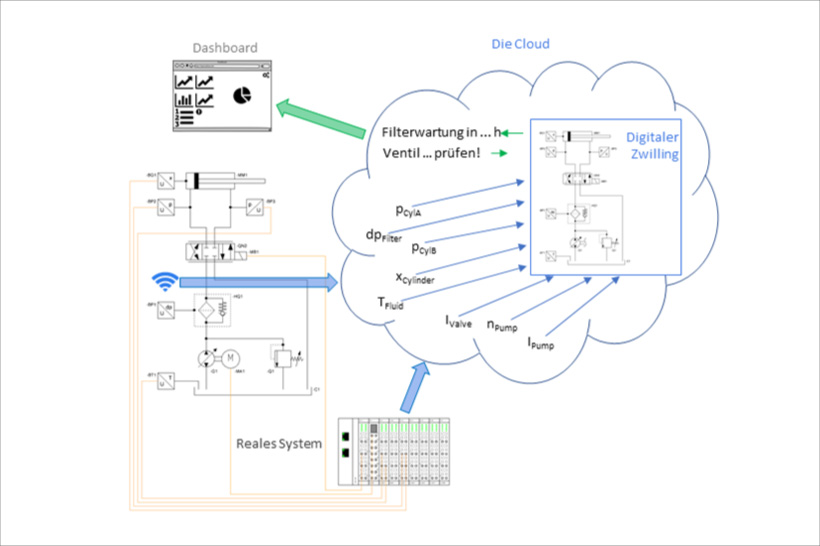
The condition of the focused components is determined by their systemic context. For example, the control signal of the valve has to be matched to the current cylinder movement profile, and the differential pressure above the filter depends on the filter load and the viscosity of the medium. These dependencies have been described in the model of the hydraulic component of the cylinder drive, the digital twin, and are included in the cloud.
First, the component manufacturer can provide physical components together with their digital twin. Technically speaking, the twin is, in this case, a simulation model package with a defined interface. The model exchange works over a Functional Mock-up Interface (FMI), a standard developed some years ago to simplify the exchange between component suppliers and OEMs. FMI protects intellectual properties while allowing the use of a model with the suppliers’ data. The model, named FMU (functional mock-up unit) after the FMI standard, becomes part of the digital twin included in the operator’s data cloud.
Second, the component manufacturer can offer components including data analysis as a service package. As this includes a data analysis which is outsourced from the system, the component supplier has access to certain data from the operator’s cloud and uses this data for the evaluation by means of his component twin. This approach works best, given that the component does not have too many logical dependencies on the rest of the system. Although many enterprises are skeptical regarding data exchange with third parties, both sides can benefit. If the manufacturer gets information about the performance of components under real-time operating conditions, the components can be adapted and improved accordingly.
The connected data flow between design, development, and operation of a system is enabled by the application of digital models. While simulation models were previously used mainly in the product development phase, digital twins do away with this limitation. Not only can these specific models be applied in parallel to the operating phase of the real system, but they also serve as prototypes for a new clone which can be used for future developments and can be constantly fed with real-time process data. This offers the opportunity to perform analyses based on current data of, for example, performance and wear behavior in the development phase. It reveals that for the derivation of real-time conditions based on measured data, the specific expertise and simulation competence are increasingly necessary.
However, the greatest challenge lies in the data management of cloud service suppliers. Thereby the absolute premise is a responsible handling of the sensitive data of the plant operators in a highly protected area.
Relevant information instead of mass data
Today, Industrial Internet of Things (IIoT) and Industry 4.0 have become buzzwords everyone is talking about. There is an enormous pressure to follow this technical hype. While looking for a useful and clever way to start, enterprises are faced with a vast market of data management solutions. However, the promoted data volume and its colorful visualization often lack convincing benefits. To provide relevant results to the user, the data delivered by connected components in an IIoT-capable system have to be analyzed and placed in the right context. To increase efficiency, the precise study question must be identified first. This reduces calculation times and leads more quickly to useful information.Monitoring industrial systems is not a new discovery. Equipping a system with sensors and logging their data has been a proven practice for decades. Condition Monitoring as a differentiated approach for preventive maintenance is only one example.
The real differences between conventional and intelligent systems result from the grade of connectivity and from the sensors integrated with the components used. In contrast to a conventional system, sensors in components of an intelligent system deliver data that can be analyzed according to the degree of cross-linking. This may sound easy, but the distribution of data in an industrial environment is still a great challenge, not least for security issues.
Turning data into relevant information - measurement data require intelligent handling
This is illustrated by a trivial analogy: A car’s driver is a perfect example of a human data processor. To drive a car safely, the driver has to make use of all the information his senses provide. The differences between an experienced and an inexperienced driver include knowing what information is relevant, understanding a safe operating condition, and the individual grade of system control.Inexperienced drivers tend to be overwhelmed by the amount of available information: traffic, road conditions, weather, traffic signs, pedestrians, buildings, even the radio program – all this is being perceived and considered by the driver. The analysis of this data is time-consuming, and hopefully, his skills are sufficient to react correctly.
An experienced driver, on the other hand, is able to filter the incoming information much better, knowing the relevant bits in the data stream affecting the vehicle's behavior. He has a much clearer knowledge of his car's reaction and what is relevant for a safe ride. For example, wetness on the road is more dangerous on leaf-covered streets than on a straight highway.
Having developed a model of his environment and the objects he uses; the experienced driver is able to feed this model with current data. He knows how slippery a wet road covered with leaves can be, and at which point his car is about to lose grip. Having analyzed the relevant data and using them as input to his model, he can predict how fast he can take the next curve without colliding with others.
The quality of the analysis or prediction depends on the current data, the knowledge of the system (or model) behavior, and on experience. The screening of relevant data and its manual evaluation is a suitable method for a limited amount of data and basic systems but will hardly cope with increasing data amounts and system complexity, when the full potential of new technologies like IIoT should be unleashed.
Automated processing and the Digital Twin approach
Automated data processing is a promising approach for rapid and complete data analysis. A modern data processing system can monitor millions of values in a split second, compare them to thresholds, and display warnings to the user. Yet the increasing flood of data makes it impossible to generate useful data by a simple comparison of threshold values but requires finding the needed information in context. The solution for benefiting from the full potential of larger data amounts is a change of perspective. Instead of exploiting all values, data clusters are identified and correlated. An instance for the generation of these correlations is the system model.Within an automated analysis, a state description is accomplished using an appropriate model, even if it is not directly monitored by specific sensors. In this case, the model is acting like an experienced process engineer, who can diagnose system errors on the basis of his knowledge-based concept of the system (for example, by analyzing machine noises). In addition, both the process engineer's concept approach, as well as the digital model approach, can be used for what-if scenarios. This means that based on a behavior description, it is possible to use a model for the extrapolation of current data.
A typical use case is preventive maintenance. This method aims at avoiding unexpected system failures (eg. due to worn components) by monitoring trends of certain indicators and estimating the remaining runtime until the next maintenance is required. The indicators are calculated by means of a simulation model representing a copy of the real system – the so-called Digital Twin.
Using a digital twin of the entire system for real-time processing of large data offers a whole range of new possibilities. Being able to predict any future development of a system component sounds enticing. Given that the more detailed a simulation model is, the more extensive it gets, this is directly related to the computing performance required for adequate solutions.
A model representing an entire system with all its detailed aspects would be much too slow to deliver a system state analysis in a timely manner. This can be solved by simplification and a focus on the basics, starting with a definition of which information is required. A simulation model adapted to these requirements can be calculated more quickly, and due to its smaller size, maintenance is much easier.
A typical use case is a system with a hydraulic cylinder actuator. Such systems are employed in material processing, where precision and speed are major priorities, and minimizing machine downtimes is key.
To this aim, the system is equipped with the usual sensors. A Signal Processing System (SPS) processes relevant sensor data and controls the required components. Using the latest technology, the operator is up to date and has installed a pool for all incoming data from his systems – the cloud. Although the system components come from different manufacturers, all of them are capable of transferring data to the cloud by SPS or by interfaces.
The operator’s goal is to achieve the longest possible service life of a machine while maintaining its precise operation. In this example of a cylinder actuator, this is mainly determined by the high-pressure filter and the servo valve. Therefore, the operator wants to know when these components, under the current operating conditions, have to be replaced, or at which speed the current system can be operated without affecting the product quality.
The condition of the focused components is determined by their systemic context. For example, the control signal of the valve has to be matched to the current cylinder movement profile, and the differential pressure above the filter depends on the filter load and the viscosity of the medium. These dependencies have been described in the model of the hydraulic component of the cylinder drive, the digital twin, and are included in the cloud.
Setting-up a Digital Twin
The set-up of digital twins as well as the generation of simulation models requires know-how and data. This can be a problem with regard to intellectual properties because the manufacturer of the system is not necessarily the manufacturer of the used components and has only limited access to the required data. One way to deal with this lack of information is to estimate the missing data on the basis of experience or contexts. Another way is to expand the value chain of the component manufacturer by adding new processes.First, the component manufacturer can provide physical components together with their digital twin. Technically speaking, the twin is, in this case, a simulation model package with a defined interface. The model exchange works over a Functional Mock-up Interface (FMI), a standard developed some years ago to simplify the exchange between component suppliers and OEMs. FMI protects intellectual properties while allowing the use of a model with the suppliers’ data. The model, named FMU (functional mock-up unit) after the FMI standard, becomes part of the digital twin included in the operator’s data cloud.
Second, the component manufacturer can offer components including data analysis as a service package. As this includes a data analysis which is outsourced from the system, the component supplier has access to certain data from the operator’s cloud and uses this data for the evaluation by means of his component twin. This approach works best, given that the component does not have too many logical dependencies on the rest of the system. Although many enterprises are skeptical regarding data exchange with third parties, both sides can benefit. If the manufacturer gets information about the performance of components under real-time operating conditions, the components can be adapted and improved accordingly.
The connected data flow between design, development, and operation of a system is enabled by the application of digital models. While simulation models were previously used mainly in the product development phase, digital twins do away with this limitation. Not only can these specific models be applied in parallel to the operating phase of the real system, but they also serve as prototypes for a new clone which can be used for future developments and can be constantly fed with real-time process data. This offers the opportunity to perform analyses based on current data of, for example, performance and wear behavior in the development phase. It reveals that for the derivation of real-time conditions based on measured data, the specific expertise and simulation competence are increasingly necessary.
However, the greatest challenge lies in the data management of cloud service suppliers. Thereby the absolute premise is a responsible handling of the sensitive data of the plant operators in a highly protected area.


