

GPU Sharing with Altair Grid Engine - Part II
In our previous article, we looked at the fundamentals of GPU resource scheduling in GPU Sharing with Altair Grid Engine Part I.
GPUs power a wide variety of HPC and AI workloads. Given the high-cost of GPU-capable servers and cloud instances, organizations are looking for ways to use GPU resources more efficiently.
In this article, we will explain a simple approach to GPU resource sharing that we will build on in the next article.
Configuring our cluster to share physical GPUs
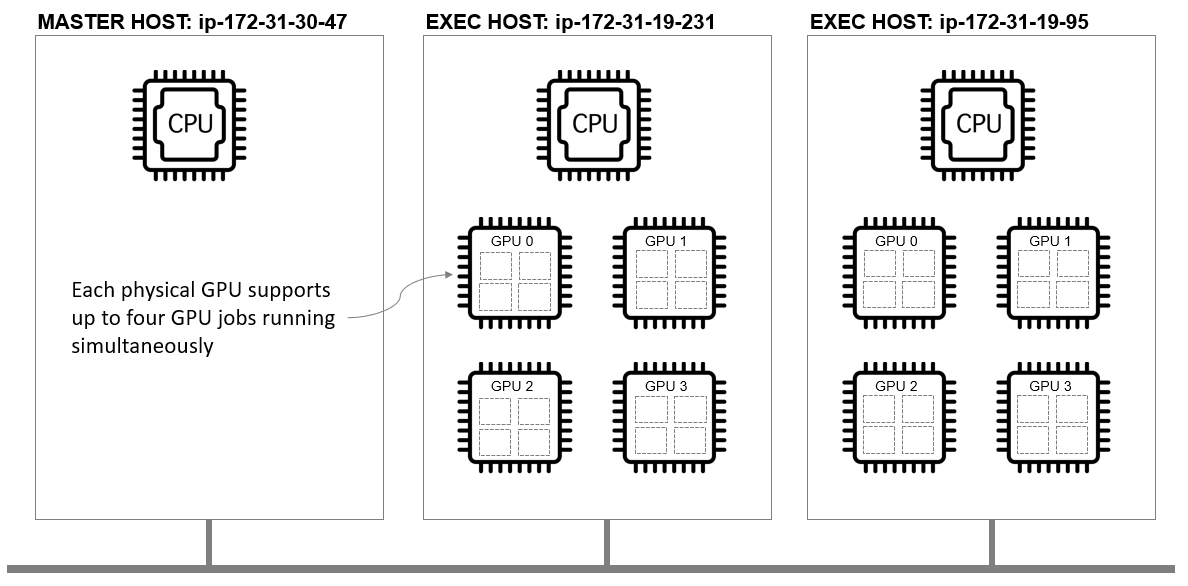
In the example in Part I of this series, we deployed a three-node cluster in AWS with a single master host and two execution hosts. Each execution host was configured so that the scheduler recognized four physical GPUs for a total of eight devices cluster-wide.
We use the same cloud-based cluster in this example:
Rather than allowing only one job to run per GPU however, we want to allow up to four jobs to run on each physical GPU simultaneously.
In some cases, applications will require a full GPU, but in others, they may only need a quarter or half of a GPU.
In this example, we assume that a gpu complex resource has already been defined on the cluster using using qconf -mc. Part I in this series explains how to add the gpu complex resource.
As before, we need to configure the gpu complex_values attribute on our two cloud-resident execution hosts (172-31-19-231 and 172.31.19.95). We will assume again that we have four physical GPUs per host, but in this case, we want to allow up to four jobs to share each physical device.
Use qconf -me as shown to configure 16 virtual GPUs and a corresponding resource map for each GPU cloud instance by modifying the complex_values line in the execution host configuration file as shown:
This syntax tells Altair Grid Engine that there are 16 available virtual GPU devices on the host and that each of the four devices can be allocated up to four times. This RSMAP syntax is flexible. We can imagine different scenarios where GPU devices are different, and we want to allow different numbers of virtual GPU jobs to run on each. For now, we'll assume each cloud instance is running the same type of GPU for simplicity.
We make the same change above to the execution host ip-172-31-19-95 which also has four physical GPUs.
Once we’ve updated the complex_values on each execution host, we can use the qhost -F gpu command to list hosts with available gpu resources.
hc:gpu=16 associated with each execution host indicates that sixteen host-level, consumable resources are available on each cloud instance for a total of 32 virtual GPUs cluster-wide.
After making these changes, our three-node cluster looks as follows, with each physical GPU allowing up to four simultaneous jobs.
Submitting virtualized GPU requests to the cluster
When a user submits a job to Altair Grid Engine, they indicate the number of GPUs (or virtual GPUs) that their job requires using a resource requirement string. With the compex_values configuration shown above, it is important to remember that we are requesting a virtual GPU – a quarter of a physical GPU given how our resource map is defined. It is up to the cluster administrator or user to know how their jobs consume GPU resources and decide whether GPU sharing is practical. Whether GPU resources can and should be shared will vary by application.
As in Part I of this series, when we use the qrsh to request a shell on a remote host, we can verify that that host granted resources shell variable ($SGE_HGR_gpu) is set and that we are returned a GPU id.
Ensuring exclusive access to a GPU
Some applications will require exclusive use of a GPU, or a job may need half or three-quarters of resources on the same GPU. It is tempting to think that we can request exclusive access to a GPU by simply requesting four virtual GPUs, but unfortunately, this will not work.
The scheduler sees 16 virtual GPUs per host, so asking for four vGPUs can result in different vGPUs being assigned from different devices. In the example above, two vGPUs scheduled by Altair Grid Engine reside on CUDA device 0, and two vGPUs reside on CUDA device 2. This doesn’t work when our application needs exclusive access to a single GPU.
Fortunately, Altair Grid Engine supports XOR (exclusive or) functionality when selecting resources defined by resource maps. If we want to ensure all selected vGPUs are on device 0 or device 1, but not some combination of both, we can use the following syntax in our resource requirement string: -l gpu=4(0^1).
We have four possible CUDA devices (0,1,2 and 3) on each instance in our example. Syntax such as (0^1^2^3) is awkward, so Altair Grid Engine provides a convenient shorthand syntax (^). This implements the XOR function across the resource map and forces all vGPUs selected reside on the same physical GPU as shown:
When this XOR syntax is used, Altair Grid Engine will return a string of CUDA devices IDs guaranteed to be the same. CUDA_VISIBLE_DEVICES is expected to contain a single device ID, so we can use a simple script as show to parse the hot granted resource to return a single device id.
A complete GPU sharing example
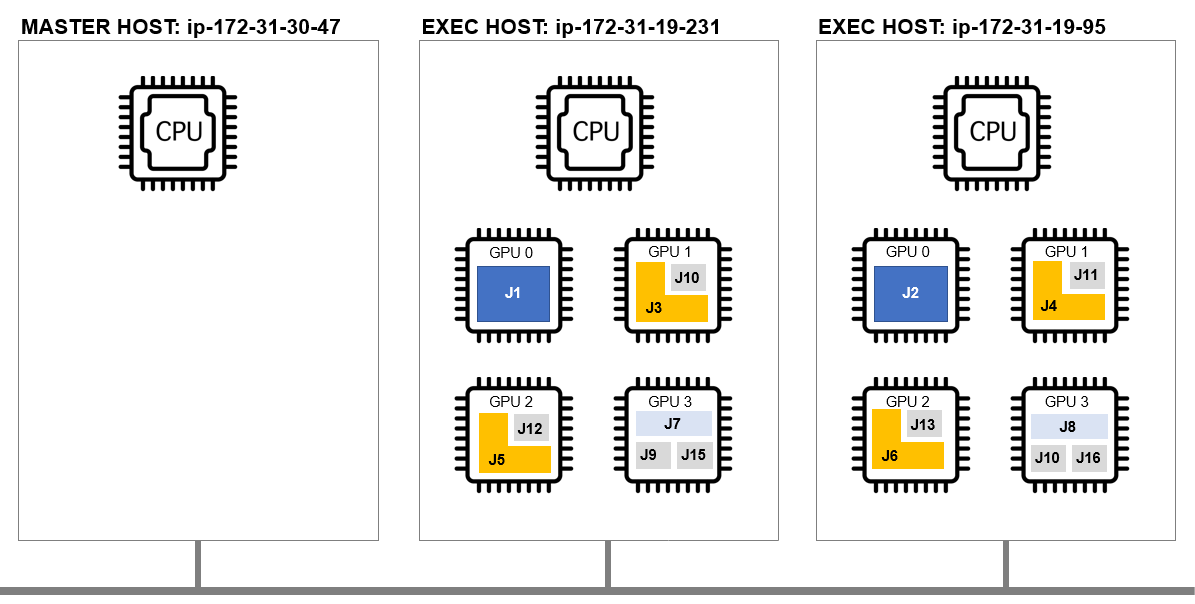
Our cluster has two nodes each with four physical GPUs and 16 virtual vGPUs for a total of 32 vGPUs. We can imagine a scenario where some jobs require a quarter of a GPU or less, while others require half, three-quarters, or a full-GPU.
The script below submits sixteen GPU-aware jobs of various sizes, to illustrate how Altair Grid Engine can effectively pack jobs to maximize the use of GPU capable instances.
We execute the script as shown:
Running qstat -F gpu shows where jobs are running as well as GPU utilization. We see that eight jobs are running on each GPU equipped host. The qstat command shows hc:gpu=0 indicating that all 16 virtual GPUs are in use on each host.
To determine where individual GPU workloads are running, we can use the qstat command, as shown below. Job 558 (labeled as job 5) is running on the host ip-172-31-19-231.ec2.internal and is consuming three virtual GPU slots (as expected since it requested 75% of a GPU) on CUDA device #2.
The diagram below illustrates how the 16 jobs are scheduled across physical GPUs in this example. Note that without GPU sharing, only 8 jobs would be able to run at the same time (one job per GPU).
In Part III of this series, we will discuss how we schedule workloads and share GPU resources in cases where GPU resources are heterogeneous across the cluster.
We will also look briefly at more advanced use cases such as cgroups, GPU affinity, and topology masks.


