

Mission Is Possible: Tips on Building a Million Core Cluster
Building a million core cluster isn’t easy, but here are some tips to help set you on the right path to achieving extreme scale HPC
When Amazon approached us to build another one million core cluster, this time with a real live customer doing production workloads, I was reminded of a popular Richard Branson quote:
“If somebody offers you an amazing opportunity, but you are not sure you can do it, say yes – then learn how to do it later!”
Of course, we said we could do it, but not as much because of the quote but because extreme scale is our business. And while we fully expected to face new challenges, we felt the collective team comprising the “best and brightest,” coupled with some late nights, would crack this and demonstrate some brilliant results. We were right.
Let’s take a quick look at the solution from the customer perspective to give you some initial context. Western Digital wanted to continue their legacy of innovating and was looking to the cloud to determine how virtually unlimited scale could allow them to solve business problems faster. Essentially what they wanted to do was to run 2.5 million verification tests in 8 hours on 1 million cores in the cloud, versus taking 20 days to run this on a discrete on-premise cluster. With 20 days expedited down to 8 hours…those are game-changing time to market gains! The team came together to plan and execute this with members from AWS, [Altair] and Western Digital.
In this blog, I explain the challenges of building such a cluster and how our team was able to resolve them, in an effort to establish a more detailed blueprint for running workloads at an extreme scale.
So let’s take a look at the challenges that we faced as we progressively stepped up our testing to larger and larger clusters with more workload. Much like peeling an onion, we identified and resolved issues that took us to new levels of scalability, but each time we would ultimately find a new bottleneck to be addressed.
In short, the standard methods for building and managing clusters in the cloud DO NOT APPLY at extreme scale. DNS servers, API performance and restart mechanisms all work well out of the box at a normal scale. But when you get to these super-sized clusters, things start to break, as there is far too much activity and communication between all of the factions to be managed in the traditional manner.
To elaborate, an extreme scale cluster is different from a standard on-premise cluster because of its highly dynamic nature. First of all, these extreme-scale clusters need to use spot instances to be cost-effective, which means that machines come and go as spot instances are reclaimed. We saw a reclaim rate of approximately 10-25 instances per minute that meant new instances had to be provisioned, jobs needed to be cleaned up in the scheduler and new jobs needed to be started where the jobs on the reclaimed instances left off. Side note: It was great that WDC’s containerized workload did checkpointing, as that made the restarts much more efficient. By comparison, on-premise clusters are sitting available for you, and it is relatively rare for a physical node to come off the cluster during execution.
In the cloud, we want to load work as the cluster spins up to avoid waste (i.e., you certainly don’t want to wait for the full 1 million cores before starting work), and we were adding instances through the spot fleets API at a rate of 675 per minute. At the same time, instances were going away and 1000s of jobs per second were being submitted, which resulted in increasing the work for the scheduler exponentially. With a static cluster, the scheduler is mostly focused on job submission and completion and isn’t worrying about such a high rate of new and disappearing instances. S we needed a new mechanism for handling this infrastructure.
So let’s start peeling back that onion and looking at the challenges we faced and how we adapted the infrastructure to deal with each of them.
Challenge #1: We knew out of the gate that fetching large containers from a container registry was going to greatly slow down the provisioning of the instances and could quite possibly overwhelm the Docker registry. We decided to bake the workload Docker images into the Amazon Machine Image (AMI) so they were ready to roll once the instance was up and running
Challenge #2: The standard AWS DNS used within VPCs did not perform at nearly the level required at this scale. To resolve this, we implemented a custom DNS in the solution and used direct IPs for reverse looks up to maximize raw speed and avoid DNS latency and throttling.
Challenge #3: API calls can be very expensive at scale so we needed a better way to monitor the cluster and manage activity as instances came and went. When newly launched instances came online, they registered their specs (instance type, IP address, vCPU count, memory, and so forth) in an ElastiCache for Redis cluster. Navops Launch then used this data to find and manage instances, which is more efficient and scalable than making AWS API calls to detect new instances.
Challenge #4: Related to challenge #3, the overall solution needed a new high-performance monitoring and management infrastructure for handling instance addition and attrition, job restarts and cluster performance. This is where we put in place some new infrastructure as part of Navops Launch. We used ElastiCache, Grafana, Prometheus and even built our own high-performance distributed RPC solution we called Fantasia (see the diagram below that outlines the various components and their roles).
Challenge #5: We needed a mechanism to get fast read access to large amounts of data across 40,000 instances. We used Amazon Simple Storage Service (Amazon S3) as the storage back-end for this run. Being able to support this fast rate of data access at such massive scales required minimal tuning effort, as S3 bandwidth scaled well and peaked at 7500 PUT/s.
Altair's Architecture for Extreme Scale

Following are some data and statistics on the run that readers may find interesting and that may help fill in some blanks:
- We completed 2.5 million tasks in less than 8 hours.
- The jobs spanned all six Availability Zones in the U.S. East (N. Virginia) region. The cluster grew to one million vCPUs in 1 hour and 32 minutes and ran at full capacity for 6 hours.
- When there were no tasks to dispatch or run, Altair Navops Launch began to shut the instances down and completed shut down of the entire cluster in about 1 hour.
- Altair Grid Engine was able to keep the instances fully supplied with work over 99% of the time.
- The run used a combination of C3, C4, M4, R3, R4 and M5 instances.
Navops Launch console showing number of instances, number of cores, instance types, utilization and job details:
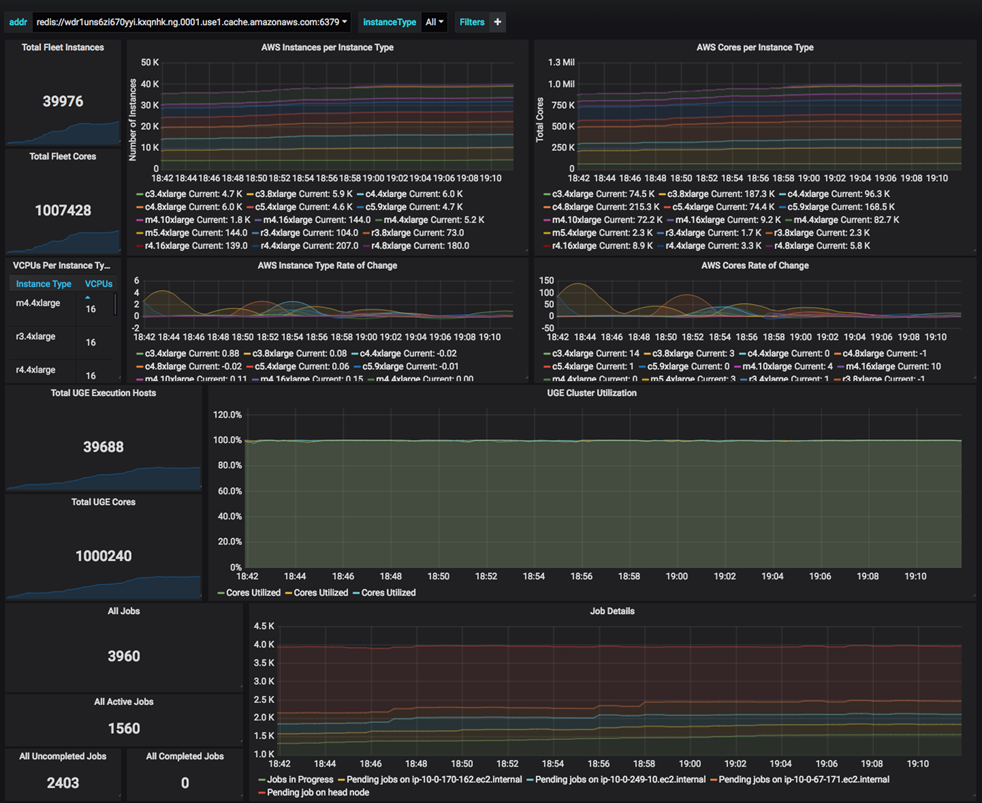
Impressive cluster utilization at 1 million cores:

What strikes me most about the success of this project is that it demonstrates that companies can reconsider entirely how they manage HPC workloads. Access to essentially unlimited compute capacity changes the competitive landscape decisively and can help organizations deliver higher-quality products to market faster. Isn’t that part of the beauty of the cloud? It costs the same in the cloud to get 2.5M tasks done in 8 hours on a 1M core cluster as it would take to spend 80 hours on a 100K cluster.
For more background on this project, you might enjoy reading Jeff Barr’s blog post on Western Digital HDD Simulation at Cloud Scale or the article by Bala Thekkedath on Extreme Scale HPC: How Western Digital Corporation leveraged the virtually unlimited HPC capacity on AWS -- in their quest to speed up innovation and build better products.
Want to learn more about how you can dramatically increase your competitiveness in the cloud? Contact us today.


