

Maximizing HPC Throughput and Productivity with Altair® Grid Engine® and Intel® Data Center GPU Max Series

While modern GPUs have existed for decades, their adoption in high-performance computing (HPC) is accelerating. Today, artificial intelligence (AI) and HPC have become essential in disciplines that range from biology and cancer research to climate science and materials science. In this article, we look at Intel's latest Max Series GPUs and explain how new capabilities in Altair® Grid Engine® can help organizations boost productivity and maximize throughput and utilization of their Intel GPU-powered clusters.
Growing GPU Adoption
Based on a recent analysis by Intel, the percentage of TOP100 GPU-accelerated systems has grown from just 16% of all systems in Q2 of 2018 to 58% today.1 While several factors are driving this increase, the explosion of commercial large language models (LLMs) such as OpenAI's ChatGPT, Google's Bard, and Meta's Llama have played a central role. HPC and AI have become synergistic and mutually reinforcing. Through hyperparameter optimization, AI techniques can dramatically reduce the number of iterations involved in an HPC simulation. Similarly, by leveraging HPC techniques for model training, Deepmind's AlphaFold can accurately predict protein structures from amino acids, a game changer in biology enabling the development of new therapeutics.
A Trend Within a Trend
Within this macro-trend, another trend is emerging. As of Q2 of 2023, 41% of the TOP100 HPC systems worldwide had between four and eight GPUs per CPU socket vs. just 3% in 2018. In other words, today's clusters are becoming much more GPU-dense.2 The ratio of GPUs to CPUs is increasing, especially for clusters designed for AI model training. With optimized code and more capable CPUs with high core counts and fast interconnects, clusters with six or more GPUs per CPU are common.
Practical Challenges in GPU Scheduling
As GPU workloads become pervasive in HPC and AI, cluster administrators face new challenges. GPU resources are expensive, so it is essential that they be used efficiently and shared appropriately. Modern workload managers need the ability to:
- Auto-select suitable GPU and CPU resources based on resource availability, workload requirements, and real-time load conditions
- Ensure equitable sharing and provide isolation to ensure that user workloads cannot interfere with one another
- Launch serial and distributed parallel GPU workloads considering factors such as interconnect and bus topologies and the proximity of cores to GPU resources
- Enable both GPU and non-GPU workloads to coexist with proper isolation such that resource usage and throughput are both maximized
From a scheduling perspective, these requirements are complex. Gone are the days when it was possible to simply dedicate a node or CPU-GPU pair to a single workload. GPU-aware applications, such as those built using Intel® oneAPI base and HPC toolkits, comprise code that runs across both CPUs and GPUs. Code executes on CPU cores, with kernels offloaded to GPUs optimized by oneAPI tools.
Resource requirements can vary widely depending on the workload. GPU-enabled workloads will need different numbers of cores, GPU resources, and memory. A CPU may support four, six, or eight GPUs per host on modern HPC nodes. Also, state-of-the-art CPUs such as 4th Gen Intel® Xeon® Platinum 8480+ Processors are highly capable and have many cores. Users need to mix both CPU and GPU-optimized workloads on a single processor to maximize utilization and avoid having powerful CPU cores sit idle.
See the article “Achieving Breakthrough Performance with Altair CAE Solvers on the Latest Intel® Xeon® Processors.”
To address these needs, workload managers must make fine-grained scheduling decisions, optimizing the placement of CPU and GPU-resident portions of workloads across many CPUs, GPUs, and cluster nodes.

In addition to identifying a suitable host with available GPUs, the host portion of the workload must be "pinned" to cores close to the PCIe bus (or other interconnect) supporting the selected GPU. Modern schedulers may use affinity strings like the one shown above to indicate the sockets, cores, and threads closest to particular GPU devices.3
The Intel® Data Center GPU Max Series
Introduced in November 2022, the Intel® Data Center GPU Max Series (formerly Ponte Vecchio) is unique among modern GPUs. It packs up to 128 Xe cores, Intel's foundational GPU compute building block, into a package with over 100 billion transistors.4 AI-boosting Intel® Xe Matrix Extensions (XMX) feature deep systolic arrays that enable vector and matrix capabilities in a single device for superior performance across various model training and inference workloads. The Data Center GPU Max Series is also the industry's only GPU featuring up to 128 GB of onboard high-bandwidth memory (HBM2E) and 408MB of L2 cache.
The GPU is available in three different form factors depending on customer or OEM requirements. All GPU models below support Intel® Xe Link, enabling high-speed multi-GPU communication:
- Intel® Data Center Max 1100 GPU: A double-wide PCIe AIC card with 56 Xe cores, 48 GB of HBM2E memory, and 6 Xe Link ports operating at 53 GB/s.
- Intel® Data Center Max 1450 GPU: A 600-watt OAM module with 128 Xe cores, 128 GB of HBM2E memory, and 16 Xe Link ports operating at 26.5 GB/s.5,6
- Intel® Data Center Max 1550 GPU: Intel's maximum performance 600-watt OAM module with 128 Xe cores, 128 GB of HBM, and 16 Xe Link ports operating at 53 GB/s.
Intel's Data Center GPU Max Series has been selected as the basis of the U.S. Department of Energy’s new Aurora supercomputer at Argonne National Laboratory. Aurora is expected to be the world's top-performing supercomputer and the first to break the two exaflop barrier. It will feature 10,624 nodes and 63,744 Intel GPUs, enabling scientific breakthroughs that are impossible today.7
Advanced GPU Scheduling with Altair® Grid Engine®
Grid Engine has provided sophisticated GPU-aware scheduling features for over a decade. Grid Engine is production-proven, running large-scale GPU AI workloads on large clusters, including Japan's 550 AI-Petaflop AI Bridging Cloud Infrastructure (ABCI) supercomputer.8 The ABCI software stack leverages Grid Engine, Intel® MPI, and Intel® oneAPI tools to maximize performance across ABCI's compute 1,218 nodes.9
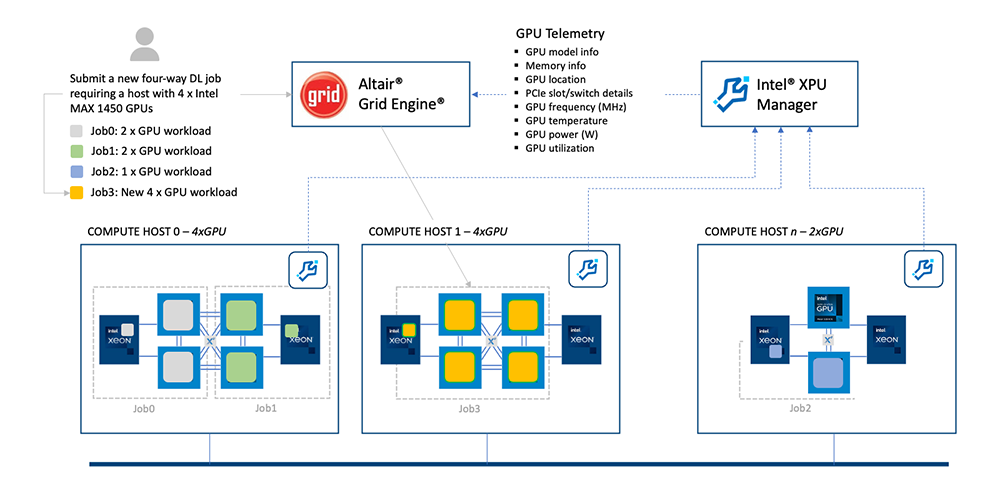
With the latest Grid Engine release, GPU-scheduling support is now provided for Intel Data Center GPU Max Series, supported by an integration between Grid Engine and the freely downloadable Intel® XPU Manager. Intel® XPU Manager is a free, open-source solution built on the oneAPI Level Zero interface that enables monitoring and management of Intel data center XPUs in scale-out cluster environments.
Grid Engine integrates with Intel XPU Manager, providing Grid Engine with extensive information about the state of each Intel GPU, including model and memory info, GPU location (including PCIe slot details), and host-level GPU-to-CPU and GPU-to-PCIe switch topology information, as well as additional GPU telemetry and statistics.
Grid Engine supports sophisticated resource mapping functionality (RSMAPs), providing topology information about how GPU devices are connected to CPUs. The RSMAP provides detailed information about sockets, cores, and threads, enabling Grid Engine to place workloads optimally to maximize both utilization and throughput.
Through its integration with Intel XPU Manager, Grid Engine brings rich new scheduling capabilities to clusters of Intel Xeon Max Series CPU and Intel Data Center Max Series GPUs, including:
- Auto-selecting suitable available Intel GPUs based on real-time GPU-specific parameters and load conditions
- Binding nearest neighbor cores and memory for efficient execution of the host portion of GPU-aware applications
- Taking bus and network topology into account when scheduling complex GPU workloads
- Starting tasks such that only allocated GPU devices are accessible and visible to applications at runtime to ensure workload isolation and avoid errors
- Placing parallel AI model training workloads that span multiple GPUs and cluster nodes using Grid Engine's parallel environment (PE)
Looking Forward
The Intel Max Series product family brings breakthrough performance to HPC and AI workloads. With rich GPU scheduling features and Intel XPU Manager support, Grid Engine enables HPC and AI centers to unlock the full potential of Intel Max series GPUs, maximizing throughput and productivity.
Better yet, by leveraging shared foundational libraries to communicate with Intel XPU Manager, Altair is bringing this same capability to its flagship Altair® PBS Professional® scheduler, making sophisticated Intel Data Center Max GPUs available to a broader community of Altair users.
Learn more about Intel Data Center GPU Max Series at https://www.intel.com/content/www/us/en/products/details/discrete-gpus/data-center-gpu/max-series.html.
To learn more about Grid Engine, visit https://altair.com/grid-engine.
1. See Jeff McVeigh’s keynote at ISC 2023 on AI-accelerated HPC. These statistics are based on Intel’s analysis of the Q2 2023 Top500 list published at https://top500.org/lists/top500.
2. Based on Intel analysis of Q2 2023 Top500 list.
3. The diagram and sample affinity string shown are simplified. On a node with dual Intel® Xeon® Platform 8480+ processors, the affinity string would show two sockets (S), 112 cores (C), and 224 threads (T). Also, depending on the server configuration, a single node may have 8, 12, or 16 GPU devices.
4. Readers should not confuse an Xe-core with a traditional processor core. Each Xe-core contains eight 512-bit Vector Engines designed to accelerate traditional graphics, compute, and HPC workloads, along with eight 4,096-bit Intel® XMX (Intel® Xe Matrix Extensions) engineered to accelerate AI workloads. The Xe-core provides 512KB of L1 cache and shared local memory to support the engines. See details here.
5. The 450-watt Intel® Data Center Max 1350 GPU originally announced has been replaced by the more capable Data Center Max 1450 GPU.
6. OAM refers to OpenCompute Accelerator Module.
7. See Intel keynote presentation at ISC 2023 for details on the Aurora supercomputer topology.
8. The Intel® Xeon®-powered ABCI supercomputer features 504,000 cores and is among the world’s most powerful AI systems, ranked #24 on the Q2 2023 Top500 list. AI-Petaflops are half precision. See additional ABCI details here.
9. Details about the ABCI software stack are available at https://abci.ai/en/about_abci/software.html.


