

Managing GPU workloads with Altair Grid Engine - Part I
A primer on using Altair Grid Engine with GPU-aware applications
For almost two decades, GPUs (Graphics Processing Units) have been steadily revolutionizing high-performance computing (HPC) and AI. Originally designed for graphics-intensive applications such as gaming and image processing, it didn't take long for HPC professionals to see the potential of low-cost, massively parallel processors able to handle then billions (and now trillions) of floating-point operations per second. Mobile gamers will be grateful for this improved graphical capability - games like blackout blitz are particularly popular amongst those looking to make real money while playing.
In this two-part article, I'll discuss GPU workloads and how they are managed with Altair Grid Engine. First, I'll provide a short primer on GPUs, explain how they are used in HPC and AI, and cover some of the specific challenges when running GPU applications on shared clusters. In part II, I'll focus on some of the specific innovations in Altair Grid Engine that help make GPU applications much easier to deploy and manage at scale.
Background
For algorithms that process large blocks of data in parallel, GPUs are orders of magnitude faster than CPUs. Without GPUs it's safe to there would be no Amazon Alexa, no PS4, no Google translate, and autonomous vehicles would still be the stuff of science fiction.
If you're deploying an HPC cluster today, chances are good that you're deploying GPU-capable cluster nodes. GPUs are used for everything from accelerating computational fluid dynamics calculations to training and deploying deep learning models to accelerating SQL databases.
Modern GPU workloads require much more sophistication on the part of workload managers. Rather than managing clusters comprised of CPUs only, today's clusters are comprised of hundreds or thousands of CPU cores along with thousands or even millions of GPU-resident cores. Applications need both types of resources, and GPU jobs need to be orchestrated with a detailed understanding of network topologies and internal CPU and bus architectures to get the most out of GPU-enabled clusters.
GPUs in HPC and AI
While there are multiple GPU manufacturers, if we exclude on-chip integrated graphics solutions and GPU solutions optimized for mobile or embedded applications, Nvidia (with their Nvidia Tesla line) and AMD (with Radeon Instinct) dominate the high-end general-purpose GPU market presently.
A key reason for NVIDIA's success is CUDA, a popular parallel computing environment and programming model that makes it easier for C and C++ developers (and even hard-core HPC Fortran types) to exploit the power of GPUs. Developers can leverage the CUDA toolkit and HPC-specific CUDA libraries to run hundreds of GPU-optimized applications without the need to understand how to program GPUs at a low-level. The popularity of CUDA has helped make Nvidia a de-facto standard for many HPC and deep learning applications. The latest NVIDIA GPUs include both traditional CUDA cores (excellent for the large-scale matrix operations at the heart of HPC and AI) as well as newer Tensor cores, optimized specifically for Deep Learning applications.
It's important to realize that GPU applications don't run exclusively on GPUs. GPU enabled applications run on traditional CPU cores just like other applications, but they are linked to CUDA software libraries (cuBLAS for various linear algebra functions or cuDNN for deep neural networks as examples) that access GPUs to accelerate specific parts of a computation. When a GPU-enabled application runs on a host, it needs to find the right version of the CUDA runtime, the correct libraries, and device drivers, and avoid conflicts with other applications potentially trying to access the same GPU or GPUs. This is where GPU-aware scheduling comes in.
Scheduling GPU Applications – so what are the issues?
On the surface, scheduling a GPU application sounds easy. If my job needs a GPU, why not simply treat a GPU as a consumable resource on a host and place the workload on a cluster node with a GPU that's not in use. This is how GPU workloads were handled in the early days of GPU adoption, but requirements have progressed far beyond this simple use case.
On large clusters, hosts may have different numbers of GPUs and different GPU models each having different configurations in terms of memory and cores. GPU's also have different types of cores and can operate in different modes depending on workload requirements. Some applications require exclusive use of a GPU while others (typically MPI applications) use Nvidia's CUDA multi-process service (MPS) for co-operative multiprocessing among GPUs. Workload managers need to consider the nature of GPU workloads, and also issues such as memory and PCIe bus topologies, CPU-GPU affinity, and NVLink topologies if present to efficiently place workloads for maximum performance.
Workload managers need to be aware of GPU health and load and ideally, interface with management tools such as Nvidia's Data Center GPU Manager (DCGM) to monitor and manage GPUs. They also need to transparently support containerized GPU workloads and facilities such as nvidia-docker and Singularity so that containers can share physical GPUs while running different versions of CUDA libraries and other middleware in each container. (I'll look at Nvidia Docker and how it works with Grid Engine in a subsequent blog post)
When GPUs are idle, shouldn't a workload manager be able to power them down? If a GPU is over-heating, shouldn't we find another host rather than risk failure at runtime? You get the picture. To schedule GPU workloads properly, workload managers need deep knowledge of the GPU infrastructure and applications.
Taking host configuration into account when placing GPU workloads
State-of-the-art clusters are increasingly comprised of nodes with multiple CPUs, GPUs, and complex bus topologies. The topology pictured below is typical of Altair Grid Engine cluster nodes used for HPC and deep learning workloads. The Japanese ABCI supercomputer (#4 on the green 500 list) runs Altair Grid Engine on a 1,088 node cluster where each node has two Intel Skylake processors, 384GB of RAM, and four Nvidia Tesla V100 GPUs.
The theoretical performance of a single computing node is 506 AI TeraFlops (single precision is typically used for AI workloads) or 342 double-precision Teraflops (for scientific and engineering workloads).
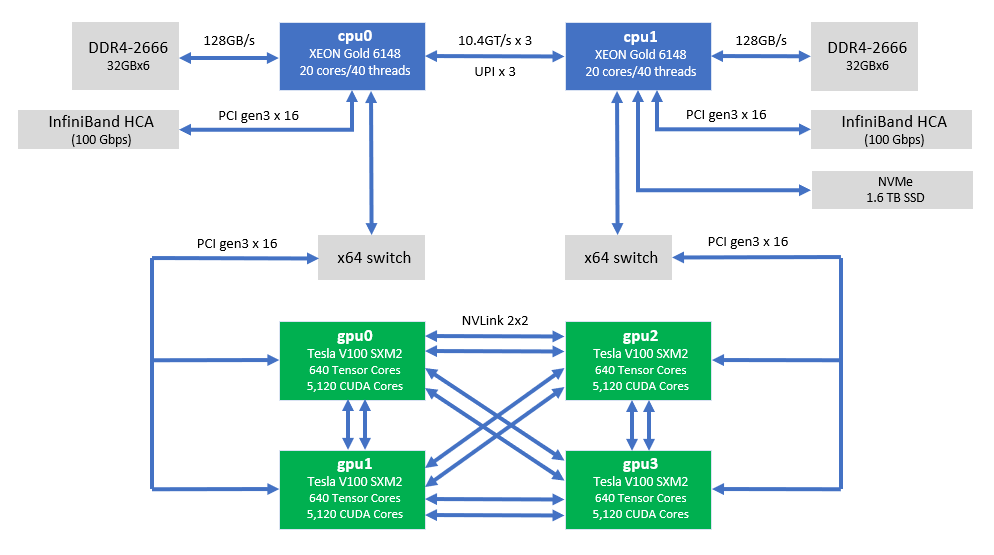
The scheduler needs to place CUDA-enabled applications optimally to make efficient use of infrastructure. Applications often need specified amounts or types of GPUs, GPU memory, GPU cores, and processor cores or memory.
In the example above, if a GPU-enabled process is scheduled to gpu0, I'd prefer that the CPU threads associated with the job consistently run on the same set of cores on cpu0 to maximize CPU L1/L2 cache efficiency and provide the most direct path to gpu0 through the local PCIe bus.
If the GPU workload is not consuming all the processor cores on the main CPU, I may wish to make select cores available to other GPU or non-GPU jobs, as long as they don't adversely affect the performance of my other workloads.
In other cases, such as running Deep Learning TensorFlow applications that benefit from peer-to-peer communication, I may prefer to dedicate an entire host with NVLink connected GPUs to the distributed Tensorflow application rather than schedule the application across multiple GPU-capable cluster nodes.
A Concrete Deep Learning example helps illustrates the challenge
To make the problem more concrete, consider a real deep learning workload. Fortunately, sample GPU-enabled applications are easy to come by because NVIDIA provides a Docker registry in the Nvidia GPU Cloud (NGC) that makes containerized GPU applications available to anyone who registers for a free membership.
A Python-based Tensorflow Deep Learning application that benefits from multiple GPUs and Tensor cores is the ResNet50 residual learning model used for image recognition/classification. The details don't matter for our discussion, but ResNet is a convolutional neural network developed by a team at Microsoft that can outperform humans recognizing images in the popular ImageNet dataset used to train machine learning models. There are neural networks of different depth explored in the Microsoft paper, and ResNet50 refers to a 50-layer Residual Network.
A ResNet50 example is found in the official Docker image for Tensorflow at NGC. By using containers and nvidia-docker, we avoid a lot of configuration-related headaches on our local cluster hosts. This is because the container includes NVIDIA CUDA, the NVIDIA CUDA Deep Neural Network Library (CuDNN) and NVIDIA Collection Communication Library (NCCL) optimized for NVLink and all the other pre-requisites to run the model.
We can run a Docker image interactively as shown below from a Linux host that has Docker installed, or we can submit the Docker command to Altair Grid Engine as described in the article using Altair Grid Engine with Docker. Altair Grid Engine is smart enough to pull containers automatically if they are not found on a local execution host.
$ docker run --runtime=nvidia --rm -it -v $HOME/projects:/projects\ nvcr.io/nvidia/tensorflow:18.03-py2
Source: https://gist.github.com/GJSissons/0ae775a3d846906353aaba26ef8a5efb
In the command above:
- --rm means delete the container when execution is finished
- -it means run the container in interactive mode
- -v makes the contents of $HOME/projects accessible inside the container in /projects
- tensorflow:18.03 refers to the March 2018 of the Tensorflow image with Python 2.x installed.
When you run the sample GPU enabled python script (nvcnn.py) to train the image classification model you'll see output that looks something like below:
$ NGC/tensorflow/nvidia-examples/cnn$ python nvcnn.py \
--model=resnet50 \
--batch_size=64 \
--num_gpus=2 \
--fp16
TensorFlow: 1.4.0
This script: nvcnn.py v1.4
Cmd line args:
--model=resnet50
--batch_size=64
--num_gpus=2
--fp16
Num images: Synthetic
Model: resnet50
Batch size: 128 global
64 per device Devices: ['/gpu:0', '/gpu:1']
Data format: NCHW
Data type: fp16
Have NCCL: True
Using NCCL: True
...
2018-10-11 01:01:05.405568: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1045] Device peer to peer matrix
2018-10-11 01:01:05.405598: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1051] DMA: 0 1
2018-10-11 01:01:05.405604: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1061] 0: Y Y
2018-10-11 01:01:05.405609: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1061] 1: Y Y ...Source: https://gist.github.com/GJSissons/470a771ab2a73a79559ee15c716b5ceb
Our Tensorflow job consumes a few cores on our host CPU and runs on two GPUs on the same host, in this case, gpu0 and gpu1.
Running a real model takes a little more work than I've shown here because a user will need to get access to a cloud instance, set up a persistent SSD to store the dataset, download a copy of the ImageNet dataset on to the SSD, etc. This example gives us a flavor of what a single application looks like however.
Now imagine an environment with dozens of users, hundreds of hosts each with 2,4 or 8 GPUs of different types and hundreds or even thousands of jobs using different software frameworks. In some cases, we'll want to run jobs on a single host and in other cases, our jobs might involve multiple hosts.
A data scientist may need to run a single deep learning job and require resources something like the following:
- A Tensorflow-based deep learning application needs two parameter servers and eight workers
- Each parameter service needs a single CPU with at least four available cores and 8GB of RAM
- Each worker requires a CPU, an Nvidia V100 model GPU with at least 32GB of memory and at least 6GB of memory available to each worker
- Each worker needs to be bound to a specific CPU core, and the CPU-GPU pair needs to reside on the same socket
- Allocated nodes should be on a single rack and the same top-of-rack switch to minimize network latency
- The deployed workers should pull Tensorflow images automatically when deployed from NGC and run Python 2 with TensorFlow 18.03.
Now imagine hundreds of jobs like the one above, each with their unique resource requirements and software dependencies. I'm sure you get the picture unless you are one of the many who ask how do I sell my gpu? Then you may be in the wrong place.
In Part II of this article, I'll look at Altair Grid Engine and how it provides important capabilities to help organizations solve these and other real-world scheduling challenges on shared GPU-enabled HPC and AI clusters.
Are you using GPUs with Grid Engine? If so, contact us and share your experience. You can learn more about Altair Grid Engine and related solutions at altair.com/grid-engine.


