

Optimizing NVIDIA DGX Systems
Building a future-proof HPC and AI cluster environment with Altair Grid Engine
In a previous article, Getting the most out of NVIDIA DGX Systems with Altair Grid Engine, we talked about the importance of GPUs for HPC and Deep Learning workloads and explained how Altair Grid Engine could help users take full advantage of NVIDIA DGX systems. As users increasingly taking advantage of GPUs, containers, and cloud-resources for high-performance applications, effective management of GPU workloads is more important than ever. With the annual NVIDIA GPU Technology Conference (now an online event) around the corner, it seems like a good time to revisit this topic.
Resource Management and DGX systems
A common issue among DGX users is how to share systems among multiple users or groups. Few organizations can afford to dedicate large-scale systems to specific users, and application environments are increasingly complex. Fortunately, for a broad range of disciplines in HPC and Deep Learning, NVIDIA provides validated containers in the NVIDIA GPU Cloud (NGC) to simplify GPU applications.1
For example, If you’re building a model for image classification, you might start with a TensorFlow container image. This image contains dozens of software packages including an OS, NVIDIA software (CUDA, cuDNN, NCCL), OpenMPI and Horovod (for parallel training), Jupyter, and other components. The sample scripts that run multi-GPU models with Horovod assign GPUs sequentially corresponding to the rank of the MPI task.2 While this keeps examples simple, it causes problems in production. For example, if four users attempt to run a 4-way training job on the same DGX-2 host, the first job will allocate GPUs 0 through 3 and the subsequent three jobs will all fail, attempting to re-allocate the same set of GPUs – all while 75% of the GPUs sit idle. Users can modify scripts or tweak the MPI command line to specify hosts and GPU devices manually, but this is tedious and error-prone. When sharing DGX systems, a GPU-aware resource manager is a far more practical solution.
A better way to run GPU applications
Resource management on GPU systems is critical for three reasons:
- It avoids having GPU jobs fail by queuing them automatically when resources are not available.
- It maximizes resource use and efficiency by dynamically allocating GPUs at runtime, boosting overall productivity.
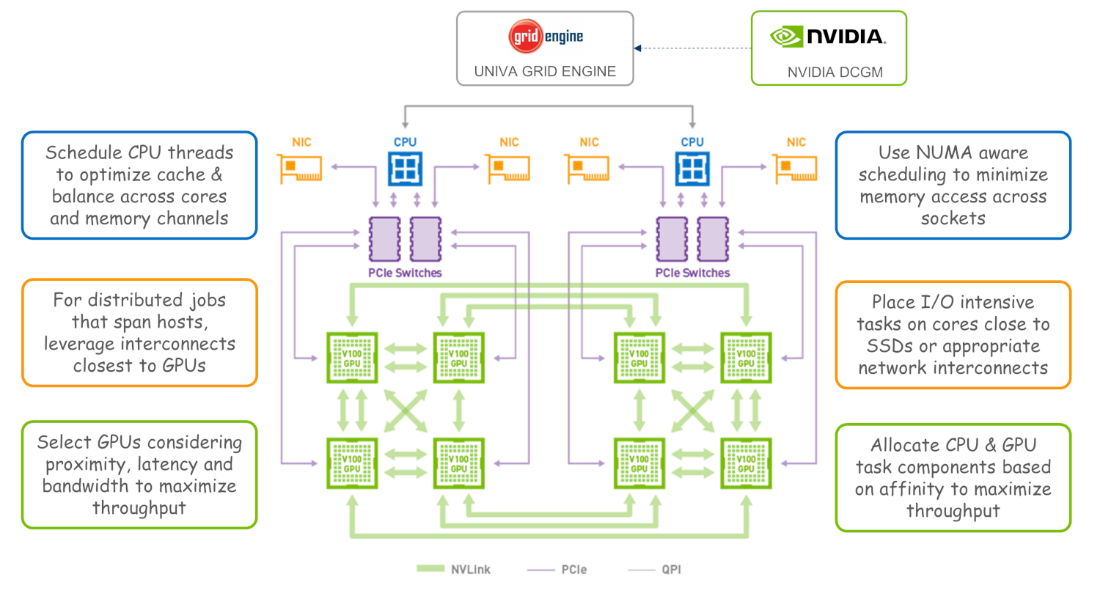
- It maximizes performance by scheduling the host and GPU portions of workloads considering the machine architecture and geometry of workloads. This includes details such as NUMA, CPU-GPU affinity, and placement strategies to balance traffic across memory channels, busses, switches, and network interfaces.
In addition to these GPU-aware scheduling capabilities, other policies are useful as well. For example, when multiple users share a DGX cluster, a fairshare policy ensures that different users, departments, or projects are allocated a specific share of GPU resources over time. Users often run a mix of CPU and GPU workloads, and in some cases, CPU jobs can consume resources and prevent GPU jobs from running. Rather than have valuable GPUs sit idle, it’s often better to automatically pre-empt low-priority CPU workloads to avoid valuable DGX assets sitting idle.
How the resource manager optimizes placement
In DGX environments, a resource manager such as Altair Grid Engine can take control of the complete cluster environment. The resource manager enforces cgroups isolation among GPUs, preventing jobs from conflicting with one another.3
When a DGX host is under control of a workload manager, the MPI runtime typically resides on each cluster host (outside application containers) and is resource manager aware. When submitting a parallel job requiring GPUs, users indicate the total number of MPI ranks, the number of ranks (GPUs) per host, and leave it to the resource manager to optimize placement.
While the resource manager knows about hosts and jobs, it doesn’t usually know about GPUs. This is where NVIDIA’s Data Center GPU Manager (DCGM) comes in. Resource managers that integrate with DCGM have real-time visibility to details such as CPU-GPU affinity, GPU memory, temperature, error rates and more. By leveraging information from DCGM, the scheduler can improve throughput, efficiency and reliability. Reporting and monitoring solutions in the resource manager can aggregate and report on these and other GPU-related metrics.
Toward a future-proof GPU infrastructure
In addition to being GPU-aware, resource managers need to run containers from NGC and other registries across DGX hardware seamlessly. The resource manager should support multiple container managers including Docker and Singularity and transparently blend containers with other workloads supporting heterogeneous applications and multiple machine architectures. While DGX systems provide ample capacity to run HPC and Deep Learning workloads on-premise, some users will want to tap GPUs and other resources from their favorite cloud provider.
Altair Grid Engine is a leading distributed resource manager that optimizes workloads and resources. Altair Grid Engine integrates with NVIDIA DGX systems and provides advanced container management, sophisticated cloud bursting, and cloud automation features with Navops Launch and works seamlessly with NGC images. Altair recently announced support for NVIDIA GPUs on Arm-based systems.
/You can learn more about Altair Grid Engine here or about extending DGX systems to hybrid cloud GPU here.
References
- See the NVIDIA Deep Learning frameworks here as an example - https://docs.nvidia.com/deeplearning/frameworks/support-matrix/index.html
- Ranks refer to the numeric designator assigned to each process in a parallel MPI job. Horovod provides an hvd.rank() method to retrieve a task's overall rank in a distributed MPI job, and an hvd.local_rank() method to retrieve the local rank starting at “0” on each server. An explanation is provided here https://horovod.readthedocs.io/en/latest/tensorflow.html
- Cgroups (control groups) is a Linux kernel feature that limits, accounts for and isolates resource usage, controlling what processes can access what devices.


