

GPU Sharing with Altair Grid Engine - Part III
Virtualizing and sharing GPU devices
In GPU Sharing with Altair Grid Engine Part I, we looked at the basics of GPU resource scheduling with Altair Grid Engine. In the second article in this series (GPU Sharing with Altair Grid Engine Part II), we explained how to configure clusters to share GPUs and provided complete examples.
In this third article, we will look at some more complicated GPU sharing use cases. We will also explore a variety of Altair Grid Engine features that will be helpful to administrators managing clusters with GPUs.
Among these use cases and features are:
- Sharing GPUs when hosts have mixed GPU types
- Dealing with GPU device ordering issues
- CUDA_ID support in Altair Grid Engine
- Integrating with NVIDIA Data Center GPU Manager (DCGM)
- The SET_CUDA_VISIBLE_DEVICES option in Altair Grid Engine
- Cgroups support to protect GPU workloads
- Topology_masks for better workload placement
Sharing heterogeneous GPU resources
In the GPU sharing examples in Part II of this series, the GPUs on each cluster host were of the same type. While host GPU devices are usually homogeneous, there may be cases where different generations of GPUs are installed on the same host. This will be more common in on-premise environments.
For example, we can imagine two clustered compute hosts, each with an Nvidia Tesla P100 card, two Telsa K80 cards, and a Telsa V100 card in each host, as shown:
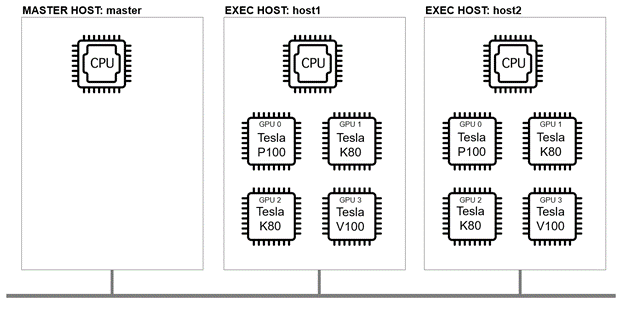
CUDA device ordering in mixed GPU environments
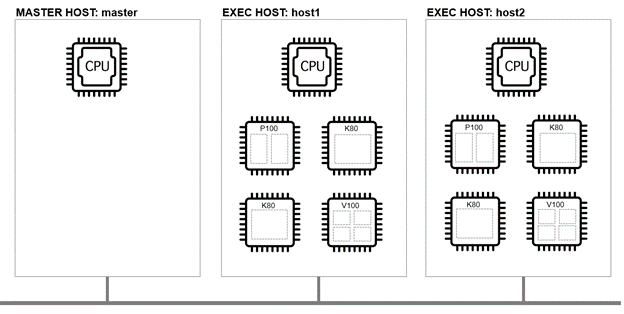
Unfortunately, we can’t assume that the CUDA device ID reported by nvidia-smi will correspond to the actual physical device we are looking for. This is because nvidia-smi by default, reports devices in the order specified in the shell variable CUDA_DEVICE_ORDER.
The default ordering policy, FASTEST_FIRST, means that CUDA will decide which device is fastest using a simple heuristic and make the fastest GPU device 0. This assignment is made regardless of the device position on the PCIe bus. This policy leaves the order of remaining devices is unspecified.
Setting the CUDA_DEVICE_ORDER shell variable to PCI_BUS_ID by comparison orders GPU devices by PCI bus ID in ascending order. This is explained in the CUDA documentation at https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#env-vars).
To illustrate the issue, we run the OS-level lspci command on host1 to show the physical GPU devices:
We might assume from this output that the Tesla P100 GPU is device 0. Running nvidia-smi on host1 (below) returns different device ordering, however. This confusion can lead users or administrators to request the wrong device if they are not aware of this issue.
To address this confusion, we need to be able to tell Altair Grid Engine what physical device corresponds to each CUDA device ID.
CUDA_ID Support
To avoid confusion, Altair Grid Engine allows administrators to map device names to both CUDA device IDs as well as the paths to the physical GPU devices.
Suppose that we want to configure GPU sharing on a host with multiple GPU types:
- The V100 card can be shared by up to four simultaneous jobs
- The P100 card can be shared by up to two simultaneous jobs
- The two K80 cards can each run only one CUDA job at a time
We can use the qconf command to implement this policy by modifying the complex_values attribute for the resource gpu on each host creating the following RSMAP:
This RSMAP definition applied to each host results in a resource sharing configuration as follows where some GPUs are can be shared (the V100 and P100), and others cannot (the K80).
With the resource complex configured, we can now schedule a job to run on a Volta 100 series GPU using a command like the one below:
This syntax tells Altair Grid Engine that a single (virtual) GPU of type V100 is required. Remember from our examples in the second article that because we have configured four V100 virtual devices, requesting a single GPU is equivalent to requesting a quarter of the physical GPU.
Once the job is submitted, if we query the job status based on the job-id, we will see the following:
As explained in Part II of this series, if our workload needs exclusive access to the full V100 GPU, we can request all four virtual V100 GPUs as shown:
Integration with DCGM
Support for NVIDIA Data Center GPU Manager (DCGM) can be enabled on a host level by setting the execd parameter UGE_DCGM_PORT in Altair Grid Engine.
This directive tells Altair Grid Engine what port to use to communicate with DCGM on the specific host (the default port is 5555).
If the DCGM port is specified and DCGM is running, Altair Grid Engine will automatically retrieve GPU load values from DCGM.
If all compute hosts are running DCGM, you can set execd_params to include UGE_DCGM_PORT=5555 across all hosts in the cluster, as shown. Otherwise, you can use the same qconf -mconf command to configure this setting for individual hosts.
With the DCGM integration enabled, Altair Grid Engine has visibility to details about all GPUs. For example. Running the qconf -se command (to show details of an execution host) shows the GPU-related load_values useful for scheduling and monitoring/reporting purposes.
For each CUDA device, Altair Grid Engine has visibility to details like the GPU temperature, socket, and core affinity (for placing the CPU-components of workloads in proximity to the GPU).
For readers not familiar with affinity strings, S, C, and T refer to cores, sockets, and threads, respectively. For each CUDA device, the topology of the CPU is mapped. Values in uppercase have a good affinity to the GPU, while devices in lowercase have a poor affinity.
Altair Grid Engine also sees GPU error conditions (to avoid placing jobs on GPUs showing an error state)
With the DCGM integration in place, we can take advantage of affinity scheduling features.
For example, to use half of the resources on the V100 processor (/dev/nvidia3) and to place the CPU component on a core that has good affinity to the GPU selected, we can submit a job as shown:
| Note: Readers may wonder in the example above why affinity is set to “2” rather than “true” or the equivalent value “1”. [affinity=1/true] represents a hard request, whereas [affinity=2] is a soft request. In the case of a hard request, all CPU cores with affinity to to the requested GPU would be blocked and the GPU would be considered unavailable to subsequent requests. In this case, there would be no opportunity to schedule a second task on the same GPU because the cores would be unavailable. [affinity=2] means “if available” (a soft request), so in this instance, all of the cores with affinity would still be scheduled for the first GPU job, but GPU can still be scheduled a second time even though there are no remaining CPU cores available. In this instance the first GPU job would have 8 cores allocated, and the second would have none, but in practice both jobs would still share the same GPU. |
SET_CUDA_VISIBLE_DEVICES
In earlier examples, we manually set the environment variable CUDA_VISIBLE_DEVICES in our scripts based on the GPU scheduled by Altair Grid Engine. The selected GPU device was returned in the environment variable SGE_HGR_gpu where “gpu” refers to the name of the resource. This ensured that the job only had visibility to the CUDA device(s) that Altair Grid Engine provided access to.
Altair Grid Engine has an enhancement that will automatically export the environment variable CUDA_VISIBLE_DEVICES for jobs when the CUDA device id defined in the RSMAP, as explained above. This feature simplifies scripting because cluster administrators no longer need to worry about setting the variable themselves.
By default, SET_CUDA_VISIBLE_DEVICES is false. It can be enabled globally or on a per-host basis. Exporting CUDA_VISIBLE_DEVICES works without DCGM, but the "cuda_id" config parameter needs to be set for each RSMAP/GPU for this feature to be used. The value returned will contain a comma-separated list of CUDA IDs assigned to a job or PE task.
You can enable the SET_CUDA_VISIBLE_DEVICES feature by adding the line below to execd_params as shown:
CGROUPS Support
Cgroups (control groups) is a feature available in modern Linux distributions that limits the resources that a Linux process (or set of processes) has access to.
Altair Grid Engine supports multiple features related to cgroups. The qconf command is used by Altair Grid Engine administrators to display or modify the configuration of the cluster. Configuration changes can be made globally such that they apply to all cluster hosts, or individually. Individual host settings will override the global settings.
To allow Altair Grid Engine to manage access to all GPUs on a host, the cgroup_path setting needs to reflect the GPU devices that Altair Grid Engine will manage.
In our example where each host has four GPUs, Altair Grid Engine will manage all devices from /dev/nvidia0 to /dev/nvidia3. Altair Grid Engine can only manage access to devices for jobs run under control of the scheduler. The cgroups feature cannot manage device access from processes running outside of Altair Grid Engine’s control.
Topology Masks
In the DCGM example above, we showed how Altair Grid Engine users could take advantage of affinity scheduling based on GPU load_values. This is possible because DCGM has visibility to what sockets and cores are closest to each GPU in terms of bus connections.
Even without DCGM, a topology_mask feature in Altair Grid Engine enables cluster administrators to express affinities between sockets, cores, and GPUs to maximize scheduling effectiveness and application performance. Cluster administrators will need to have a good understanding of the server architectures in their environment to use this feature.
As with the DCGM affinity syntax, sockets are expressed by the letter “S” while cores are expressed by the letter “C”. Upper-case “C” means that a core has a good affinity to a GPU, while lowercase “C” means that a core has a poor affinity.
The example below assumes a dual-processor host with two sockets, each with 8 cores (note that for simplicity, this example does not include CPU sharing):
Specifying RSMAPS with topology_masks enables granular control over how the host portions of GPU workloads are placed.
Suppose that we want to run a job that needs a single CPU core associated with a GPU connected on a local PCIe bus. Using the syntax below, UGE will pick a host and assign a core and GPU based on the RSMAP host-specific topology_mask.
There are a variety of binding options, including linear, linear_per_task, striding, striding_per_task, balance_sockets, pack_sockets, and others. The Altair Grid Engine qsub(1) man page explains these binding options in detail.
We can also submit a job that requests all free available cores with affinity to a GPU, as shown below. This will prevent other non-GPU jobs from being assigned to cores with affinity to the same GPU that could potentially conflict with the GPU workload.
For some GPU workloads (such as parallel MPI-enabled Deep Learning workloads), we need to schedule GPUs as parallel workloads. This is accomplished using the parallel environment (PE) features in Altair Grid Engine.
Consider an example where the allocation rule in our PE is 28 slots on each machine. We want to reserve four machines (each with 28 host slots) and four GPUs per host for a parallel job that requires 112 host slots and 16 physical GPUs.
In the example below, we create a reservation for one hour for 112 slots and four GPUs per host. We then submit the parallel workload spanning four hosts and 16 GPUs by specifying the reservation ID to Altair Grid Engine:
Wrapping up
GPU scheduling and GPU sharing are complicated topics. Hopefully, this series of articles has been a useful introduction to the topic.


